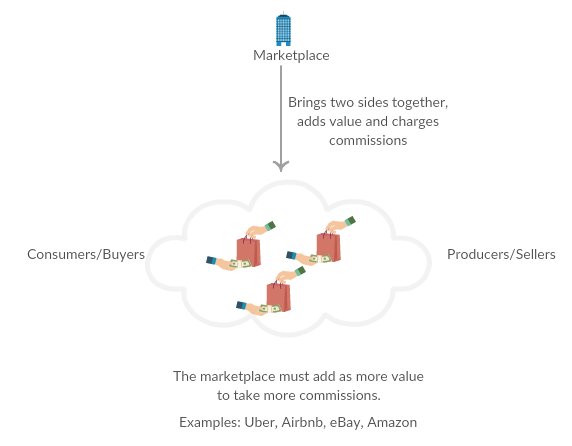
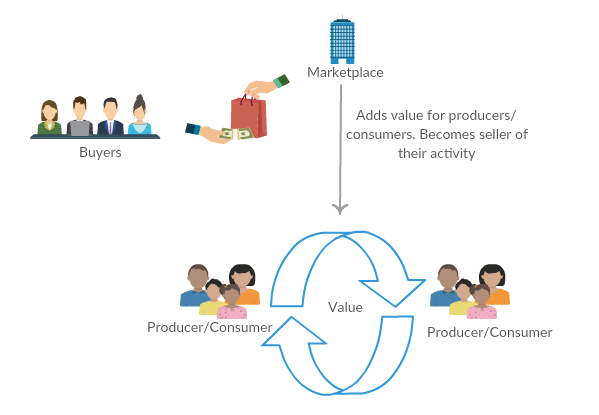
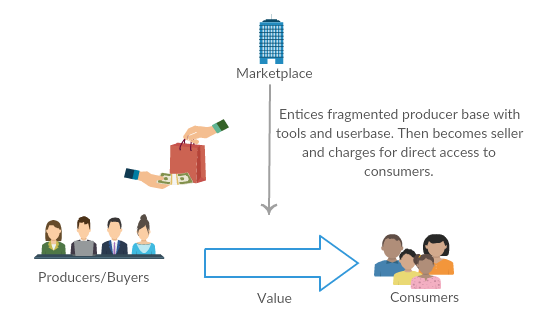
Joining a new team, let alone company, is hard during normal times. Covid-19 has made that challenging time that much more difficult because even infrequent in-person meetings have now been relegated to video chats via your company’s favorite video chat application. In that respect, even local workers have become “remote”, and all of us have become talking heads on video chat.
Under normal circumstances, a new product manager (including leads and directors) can sit in various meetings and sit together with folks from the new team. Unfortunately, an incoming product manager is expected to hit the ground running despite this new normal.
Here are 5 areas to concentrate on for building relationships, credibility and expertise in a hurry:
- Build relationships
Perhaps the most important part of a product manager’s job is to build strong relationships with the new team, supporting teams and any partners. With video chat, all of us have now become talking heads. Everyone is dealing with the pandemic in their own way, and the net result is that meetings have now tended to become transactional and not relationship-based.
In my opinion, most of the magic for a product manager happens during those extra bits before and after the actual meeting, or in the hallway, or at lunch. Additionally, I have always built strong, long-lasting relationships during travel when the team bonds on a shared trip.
With this view in mind, the best thing for an incoming product manager to do is to concentrate on building relationships. Part of this means going out of your way to do things that you wouldn’t normally do in a new job. Some ideas include setting up an info session (trust me, everyone is feeling out of the loop), bringing teams together, and frankly, just listening with an open mind.
The small chit-chat at the beginning of the meeting is indispensable and perhaps more important than ever. Strong relationships will provide you the runway needed to do your job effectively, especially when the decisions are unclear and the going gets tougher. - Build credibility
Building credibility in a new team is hard. I don’t mean expertise in the job, but really credibility as a person of integrity – what the British call “sound”. To be sound means that you know how to behave, what needs to be done in each circumstance, and in general, you won’t let the larger team down.
No one knows the awesome work that you have done before you got to the new team, and worse, no one cares. Humans are adept at building trust and credibility through body language, water-cooler talk and shared experiences like lunches and trips, but that luxury is gone during Covid-19.
So, concentrate on building credibility by communicating your principles more often than you would normally do. One tip is to over-communicate even at the risk of sounding pedantic. This is a tough balance to hit in a new team, and everyone wants to communicate just so. But keep in mind that the penalty for over-communicating is less than the penalty for under-communicating. Hence, my advice is to come out and say the obvious. You will be surprised how often others are not aware of the “obvious”.
Building credibility is very important for people managers because everyone is naturally always more worried about their own job and their place in the team. Communicating principles and beliefs early and often will allow you to form a basis for credible decisions that your team will appreciate. - Build product expertise
Ah, this is what you got to the new team to do – product management. As the title of the job itself suggests, you cannot do your job effectively unless your new product becomes second nature to you. Sadly, any product worth its salt will take you months to truly understand. There is also a lot written about this topic, so I won’t get into the details here. But suffice it to say that you should spend a whole lot of time understanding the nuances of product decisions, the history behind why things were done a particular way, and of course, why users care about your product.
One tip is to ask different people the same questions – the answers will sometimes vary and will give you a good sense of the nuances. - Build data expertise
Much has been written about this topic as well. I have personally found that being comfortable with the data takes a whole lot of effort, but it is the single best investment of your time (after building the relationships).
A strong data analysis muscle will pay dividends for months and years, but nothing makes a new PM stand out as much as turning a discussion towards data, especially when folks don’t expect you to know the details. - Build the vernacular
This is perhaps the hardest part in a new team. It always takes time to build the vernacular, but sadly, you don’t have the luxury of finding an engineer after a meeting to sit down and understand the difference between two similar-sounding but different-meaning words.
Effective communication is the domain of a strong PM, and nothing derails a meeting like a wrong word that is misunderstood differently by different people in the meeting.
There you have it. These are my early observations about 5 areas to concentrate on when joining a new team. While my view is heavily influenced by product management, this applies to any new job and most of it is obvious to any seasoned professional. Yet, I have found that even seasons professionals can forget the importance of building the relationships and data expertise, and sometimes concentrate more on vision and roadmaps. Those are important, but as I always say – “One must stand on high moral ground first before taking long leaps”.
Have fun in the new team. It is always an exciting time to learn new things and put your stamp on them.